
METHODEN UND SKILLS VON NATURAL LANGUAGE PROCESSING
WAS UNTERSTÜTZT NLP?
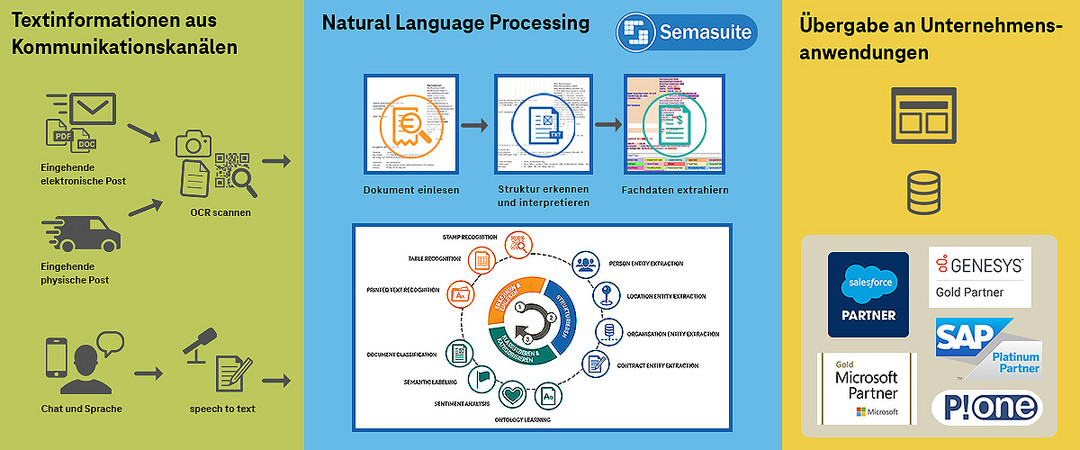
Natural-Language-Processing bildet die Verbindung zwischen vorliegenden Textinformationen aus unterschiedlichen Kommunikationskanälen und dem automatisierten Übertragen
der Erkenntnisse aus diesen Informationen in Unternehmensanwendungen, aus denen heraus anschließend - teil oder vollautomatisiert - Folgeaktionen angestoßen werden können.
Mit unserer NLP-Plattform Semasuite® stellen wir Ihnen diese Verbindung zur Verfügung. Dazu arbeiten wir mit verschiedenen Skills, um die Textinformationen auszulesen, zu strukturieren,
zu klassifizieren, zu kategorisieren und daraus die Bedeutung zu erkennen und dieses Wissen in weitere Prozesse einfließen zu lassen.
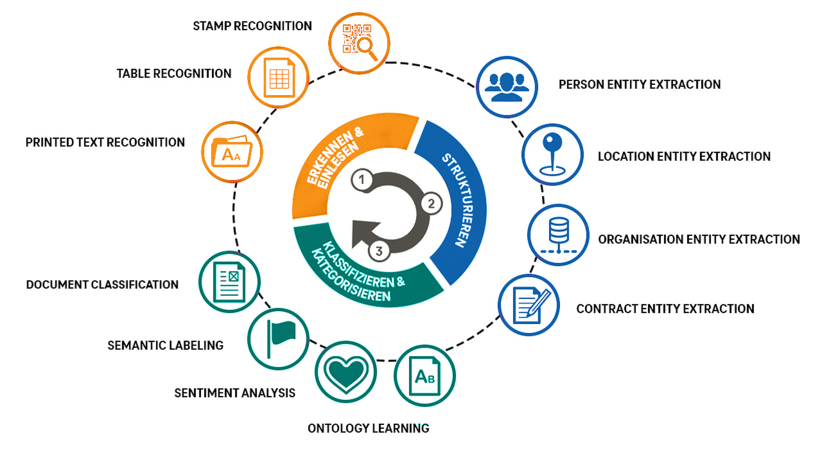
MIT WELCHEN SKILLS ARBEITEN WIR?
Jedes Projekt ist anders, jede Anforderung einzigartig. Genau wie die Sprache sich unterscheidet, sind unterschiedliche NLP Strategien notwendig. Produkte für „NLP auf Knopfdruck“ gibt es nicht!
Dem Natural-Language-Processing zugrunde liegen die Fähigkeiten der Analyse von geschriebenem bzw. verschriftlichtem Text (z. B. aus telefonischen Gesprächstranskriptionen). Was einfach klingt,
ist hochkomplex: Man denke nur an die vielen Ausdrucksmöglichkeiten wie Hoch- vs. Umgangssprache, Fachbegriffe, Dialekte, Akzente und Regeln rund um Grammatik und Satzbau.

ERKENNEN UND EINLESEN
Nicht nur in großer Anzahl, sondern auch in den unterschiedlichsten Formaten liegen Textdokumente heutzutage vor: in Briefform, Scans, als Bilddateien, QR- oder Barcode und vielen weiteren.
Das Erkennen und Einlesen dieser Formate ist die Voraussetzung für das sich anschließende Strukturieren, Kategorisieren, Klassifizieren und Prozessieren.

PRINTED TEXT RECOGNITION
Die automatisierte Texterkennung nutzt Optical Charakter Recognition (OCR) zum Erfassen des Textes aus Bildinformationen in Dokumententype wie E-Mail und PDF, Scan- und Bildformaten wie TIFF, JPEG und PNG sowie Zeichen. Dieser Erkennungsvorgang wird benötigt, da ein optisches Eingabegerät, wie z. B. ein Scanner oder eine Digitalkamera, lediglich die Pixel in Form einer Rastergrafik identifiziert und nicht die Buchstaben als Ganzes. Unsere modernen Algorithmen sind fähig, die Texterkennung unabhängig von der Schriftart durchzuführen. Wir integrieren auch Ihre bestehenden OCR-Lösungen und korrigieren Bereiche, in denen oft Fehler vorkommen durch für die Anwendung und den Dokumentbereich angepasste OCR-Methoden.

TABLE RECOGNITION
Tabellen werden generisch anhand der charakteristischen Eigenschaften, das heißt an den Zeilen, welche immer dieselbe Anzahl an Spalten aufweisen, den Abständen der Wörter oder Zahlen und der Textausrichtung interpretiert. Anknüpfend an das Erfassen von Tabellen können die Werte für die Weiterverarbeitung extrahiert und dem meist vorgegebene Datenschema entsprechende bereitgestellt werden. Ein fertiger Semasuite®-Service berücksichtigt hierbei Einträge, Referenzen und - wo notwendig - integrierte fachliche Zusammenhänge.

STAMP RECOGNITION
Um ein Dokument vollständig sichten zu können, bietet die Semasuite® auch die Registrierung von Stempeln oder anderen bildartigen Dokumentenbestandteilen an. Dabei werden definierte Merkmale mit der Anordnung erkannter Pixel verglichen, die Art des Stempels definiert und zur weiteren Verarbeitung bereitgestellt. Somit lassen sich in Folgeschritt beispielsweise Informationen wie das Posteingangsdatum herauslesen.
STRUKTURIEREN
Das Computer-basierte Erfassen der Informationen allein führt noch nicht zu einer Interpretierbarkeit der Daten. Dieses Wissen ist jedoch Voraussetzung einer sich anschließenden Analyse
und die Zugänglichkeit dazu liefert uns die Informationsextraktion. Auf ihrer Basis entnehmen wir vordefinierte Typen von Informationen (Entitäten) aus maschinenlesbaren Dokumenten,
z. B. Personendaten, Vertragsdaten und weitere wie folgt aufgelistet.

PERSON ENTITY EXTRACTION
Nachdem Texte als solche in digitaler Form und mit Strukturinformation erkannt wurden, schließt sich die Interpretation bekannter und generelle gültiger Entitäten an. Wörter, die personenbezogene Daten enthalten lassen sich einer Gruppe zuordnen, z. B. Vor- und Nachnamen.

LOCATION ENTITY EXTRACTION
Ähnlich des Extrahierens von personellen Daten, können auch Orte, das heißt Länder bzw. genaue Unternehmensstandorte oder Privatadressen aus Dokumenten gefiltert werden, um diese nachfolgend den dafür zuständigen Mitarbeitern zuzuteilen oder wiederum in eine Unternehmensanwendung wie CRM- oder ERP-System zu transferieren, z. B. Adressen und ihre einzelnen Bestandteile wie Straße, Hausnummer, Postleitzahl und Ort.

ORGANISATION ENTITY EXTRACTION
Die Textanalyse der Semasuite ermöglicht außerdem das Selektieren nach Daten einer Organisation, also beispielsweise Firmennamen, Gesellschaftsform, zugehörige Identifikations- oder Kundennummern oder Internetadressen.

CONTRACT ENTITY EXTRACTION
Semasuite bietet die Funktion, Kundenstamm- sowie nach Vertragseinheiten und vertragsrelevanten Daten zu filtern. Dies beinhaltet die Extraktion von Kundennummer, Kontaktinformationen, Bankdaten, Bestellnummer oder Lieferdatum sowie Klauseln oder Konditionen zur Differenzierung eingereichter Verträge und als Grundlage für das Ableiten weiterer Handlungsschritte.
KLASSIFIZIEREN UND KATEGORISIEREN
Die Klassifizierung von Textdaten basiert auf Daten, die aus der Vergangenheit bereits in den gewünschten Klassifizierungen vorliegen, weil entweder eine Typisierung manuell stattgefunden
hat oder im Laufe der Bearbeitung eine Klasse zugewiesen wurde. Neu hinzukommende Textdokumenten werden durch einen auf diesen Trainingsdaten basierenden und durch maschinelles Lernen
erstellten Klassifikator verglichen und bei einem Treffer einer oder mehreren definierten Kategorien zugewiesen - oder eben nicht. Die Semasuite®-Anwendung nutzt aktuelle Frameworks
für Maschinenlernverfahren, bietet für Text angepasste Feature- Modelle und eine technische Lösung für automatisierte Aktualisierung von Modellen, wenn neue Trainingsdaten vorliegen.

ONTOLOGY LEARNING
Ontologien bringen weitergehende Beschreibungen über den Zusammenhang von Daten hinzu. Mithilfe dieser lassen sich Rückschlüsse aus den vorhandenen Daten ziehen, Widersprüche innerhalb der Angaben eruieren und fehlende Informationen ergänzen. Das ontologische Lernen der Semasuite® beinhaltet den Prozess, innerhalb dessen aus sinnverwandten Begriffen durch automatisierte Verfahren (KI) weitere Erkenntnisse und Zusammenhänge akquiriert werden. Semasuite® beinhalten sowohl ein Verfahren für Ontology Learning für W3C-SKOS-Modelle als auch einen barrierefreien Ontologieeditor zu Ergänzung und Validierung von automatisiert gelernten Ontologien.

SENTIMENT ANALYSIS
Mit Hilfe einer Sentimentanalyse lässt sich ein Text auf die vorhandene Stimmung prüfen und ob eine positive oder gar negative Tendenz, z. B. eine Beschwerde oder ein Ärgernis, erkennbar ist. Die Suche nach Schlüsselwörtern bildet die Grundlage. Mit der Semasuite®-Lösung wird darüber hinaus auch der Kontext berücksichtigt und damit die Kategorisierung von E-Mails, Social-Media-Posts oder anderen Anfragen erleichtert. Sentimentanalyse ist im weitesten Sinne eine spezielle Art der Textklassifikation.

SEMANTIC LABELING
Hierbei handelt es sich um die Kategorisierung von Texten in semantisch ähnliche Einheiten. Werden zuerst lediglich Buchstaben und Wörter identifiziert, konzentriert sich diese Fähigkeit der Semasuite® anschließend auf deren Bedeutungsgehalt. Klassische Anwendungsfälle sind z. B. das Anwenden der Firmenfachsprache auf den Posteingang, das Zuordnen von Kundenanliegen zur Firmenfachsprache oder das Erkennen von Konzepten der Firmenfachsprache.

DOCUMENT CLASSIFICATION
Nachdem durch die vorangegangenen Analysen die Inhalte erfasst und interpretiert wurden, kann mithilfe der Dokumentenklassifizierung die Gruppierungen von Objekten (Dokumenten) mit gleichen Attributen oder Eigenschaften vorgenommen werden. Somit wird das Ordnen vom Anfragen automatisiert und die Zuteilung der diesbezüglichen Aufgaben vereinfacht.

DATENSCHUTZGERECHT PROZESSIEREN
Datenschutzrechtliche Regelungen verpflichten Unternehmen, personenbezogene Daten zu verschleiern, sobald der ursprüngliche Nutzungszweck nicht mehr erfüllt ist. Diese Maßgaben schränken
Unternehmen in Bezug auf eine nachträgliche Qualitätssicherung und Datenanalyse erheblich ein. Textdaten dennoch datenschutzgerecht und nachnutzbar zu prozessieren, ist dank Anonymisierung
und Pseudonymisierung möglich. Auch KI-gesteuerte Automatisierung und Business Analytics sind auf die Verfügbarkeit historischer Daten für Modelltraining, Validierung oder Analyse angewiesen.
Nur anonymisierte Daten dürfen gemäß den DSGVO-Vorschriften gespeichert oder verteilt werden. Somit sind Textanonymisierung und Textpseudonymisierung auch hier die einzig praktikablen
Lösungen für ethische KI-Anwendungen und -Analysen auf Basis kundenbezogener Daten.


Anonymisierung
Anonymisierung ist die Veränderung personenbezogener Daten, sodass die Einzelangaben über persönliche oder sachliche Verhältnisse nicht mehr oder nur mit einem unverhältnismäßig großen Aufwand an Zeit, Kosten und Arbeitskraft einer bestimmten natürlichen Person zugeordnet werden können. Die Semasuite®-Lösung zur Anonymisierung erkennt automatisiert personenbezogene Daten innerhalb eines Textes. Somit können Kundendaten, Telefonnummern, E-Mail- und Postadressen oder Zahlungsinformationen markiert oder zuverlässig anonymisiert werden.

Pseudonymisierung
Pseudonymisierung bedeutet das Ersetzen des Namens und anderer Identifikationsmerkmale durch ein Kennzeichen zum Zwecke des Ausschlusses oder der wesentlichen Erschwerung der Bestimmung der betreffenden Person. Pseudonymisierung ist dann wichtig einzeln Nutzergruppen personenbezogenen Daten für Ihre Anwendung sehen sollen, aber eine weitere Nutzergruppe an den Inhalten interessiert ist, aber die Identität der Personen nicht kennen darf. Beispielanwendungen sind Kundenzufriedenheitsbefragungen, wissenschaftliche-medizinische Studien, Lesbarkeitserhalt für Gutachter, Generalisierung bei der Pseudonymisierung von Datenfeldern für aussagekräftigere Business Analytics.